
-
[운영체제 Step 9] - 스케줄링 알고리즘 (SPN, SRTN, HRRN, MLQ, MFQ) 본문
FCFS에서 가장 문제점이 난 금방 일을 끝낼 수 있는데 앞에 있는 다른 프로세스 때문에 오래 기다려야하는 이런 불공평함이 존재했었습니다.
그래서 이를 보완하기 위해 짧은 프로세스는 먼저 빼주자는 전략이 등장하게 됩니다.

즉, 다시 말해 Burst time이 가장 작은 프로세스부터 먼저 처리하겠다는 의미로 받아들여집니다.
이를 다른 말로 Job이 가장 짧은 것 부터 처리한다는 의미에서 SJF라고도 부릅니다.
또한 한 번 할당받으면 끝나기 때문에 "비선점" 스케줄링 방식을 채택하고 있습니다.
그로 인한 장점은 여러 가지가 있습니다.

아무래도 BT가 짧은 프로세스 위주로 처리하다 보니 평균 대기시간(WT)가 적어지게 될 것입니다.
또한 시스템 내 프로세스 수를 최소화시킴으로써 스케줄링 부하가 감소되고 메모리도 절약하여 시스템의 효율을 향상시킬 수 있을 것입니다.
하지만 그로 인한 단점도 있습니다.
예를 들어 A라는 프로세스는 1시간이면 끝나는데 제일 먼저 와서 실행하려고 할 때 B,C,D 부터 Z까지 와서 기다린다고 생각해 봅시다.
그렇게 되면 A가 만약 B~Z까지 모두 1시간보다 덜 걸리는 BT라면 계속해서 대기해야하는 Starvation (무한대기) 현상이 일어날 것입니다.
이를 다른 말로 기아현상이라고도 부릅니다
즉 BT가 긴 프로세스는 자원을 할당 받지 못 할 수도 있습니다.
그리고 한 가지 더 문제가 있습니다.
프로세스의 BT를 정확히 파악할 수 있으면 좋겠지만 사실 이를 정확히 예측하기란 시스템의 성능에 따라서도 다를 수 있기 때문에 정확한 예측 기법이 필요하겠습니다.
SPN도 표를 통해서 이해해보겠습니다.
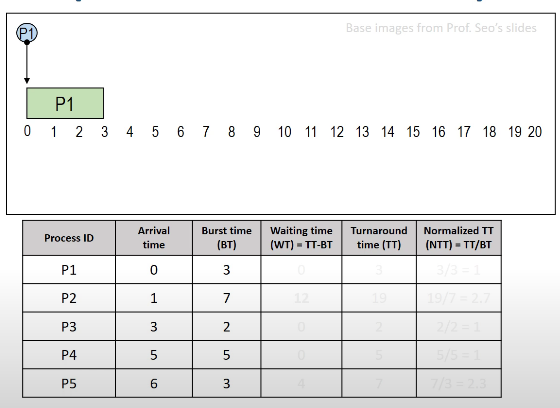
일단 P1은 제일 먼저 도착했고 아무도 없으므로 제일 먼저 실행되어 WT는 0, TT는 3, NTT는 1이 되겠습니다.
그리고 P2와 P3가 도착해있지만 P3가 BT가 더 적으므로 P3이 실행됩니다. 그래서 P3의 WT는 0, TT는 2, NTT는 1이 되겠습니다.
그럼 그 이후에 누가 실행될까요?
지금 시점은 5초가 지나있고 P4도 도착해 있습니다.
그러나 P4의 BT가 P2의 BT보다 적으므로 P4가 실행됩니다.
P4의 WT는 0, TT는 5, NTT는 1이 되겠고 13초가 되었습니다.
그 때 P5가 실행되고 P2도 이어서 실행됩니다.

이 P2는 1초에 도착해서 BT가 7이라는 이유로 무려 13초가 지나서야 실행이 되었습니다.
이를 바로 Starvation (무한 대기), 즉 기아현상이라고 부릅니다.
P2 입장에서는 상당히 불리하게 받아들여질 것입니다.
본인이 먼저 도착했는데 훨씬 늦게 도착한 프로세스들이 먼저 자원 할당을 받으니까요.
그래서 이를 보완하기 위해 남은 시간이 가장 적은 녀석을 처리하겠다는 STN의 변형 스케줄링이 등장합니다.

이 스케줄링은 잔여 실행 시간이 더 적은 프로세스가 Ready상태가 되면 선점이 되도록 장려합니다.
또한 SPN을 보완하기 위해 등장했기 때문에 SPN의 장점이었던 WT의 최소화와 프로세스 수를 최소화 할 수 있다는 점을 그대로 가지고 있습니다.
하지만 이 역시 여전히 단점이 존재합니다.
프로세스 생성시 BT의 정확한 예측이 필요한데, 잔여 실행 시간을 계속해서 추적해야 합니다.
그러므로 부하가 증가할 것이고 Context Switching이 잦아져 오버헤드가 증가할 것입니다.
게다가 이 부분들을 모두 보완하면 좋겠지만 그것이 쉽지 않기 때문에 비현실적이라는 평가를 받습니다.
그래서 SPN의 변형 중에 좀 더 현실적인 기법이 등장합니다.

들어온지 오래된 프로세스가 마냥 기다리는 것이 문제가 되어 등장했습니다.
HRRN의 가장 큰 특징은 SPN의 컨셉에 Aging Concepts를 더했다고 이해하시면 되겠습니다.
즉, 나이가 많은 프로세스. 오래 기다린 프로세스를 배려하여 (WT) 프로세스의 기회를 제공합니다.
이 Response Ratio 는 (WT + BT) / BT 로 정의됩니다.
이를 응답률이라고도 부릅니다.
필요한 시간 대비 얼마나 기다렸는가를 수식적으로 표현한 것입니다.
그래서 이 HRRN은 SPN의 장점을 가지면서도 Starvation을 방지할 수 있습니다.
하지만 실행 시간을 정확하게 예측하는 기법이 필요하다는 점은 여전히 존재했습니다.
표로 이해해보겠습니다.

일단 P1은 들어오자마자 실행되므로 이렇게 작성되겠습니다.
P2의 BT는 7이고 WT는 2이므로 Response Ratio = 9 / 7 = 1.29가 됩니다.
P3의 BT는 2이고 WT는 7이므로 Response Ratio = 9 / 2 = 4.5가 됩니다.
그 다음은 누가 되죠?
현재 Ready-Queue에는 P4와 P5가 담겨 있습니다.
P4는 5초에 도착했고 P3는 12초에 실행됩니다.
따라서 P4의 BT는 5이므로 WT는 7이므로 RR = 12 / 5 = 2.4입니다
P5의 BT는 3이고 WT는 6이므로 RR = 9 / 3 = 3입니다.
누가 더 크죠? P5이 더 크지요?
따라서 응답률이 P5가 더 크다는 의미이기 때문에 P4보다 P5가 먼저 실행되게 됩니다.

그래서 지금까지 해본걸 정리해보면요.
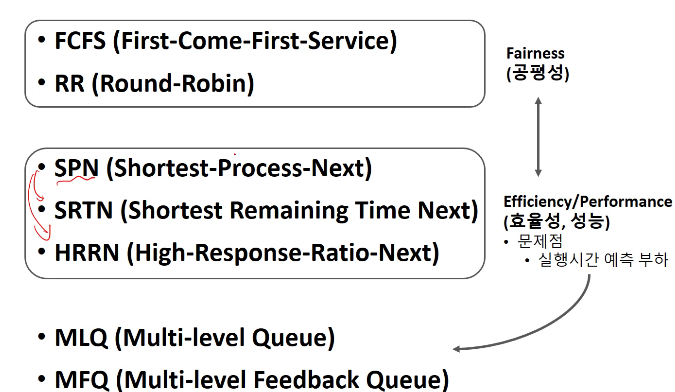
앞시간에 배웠던 FCFS와 RR은 공평성을 위주로 설명했었고
SPN과 SRTN, HRRN은 효율성과 성능을 위주로 접근했습니다.
하지만 이것들의 문제는 실행시간 예측을 하기가 힘들고 정확하지가 않았습니다.
그래서 이를 해결하기 위해 제일 밑에 소개한 MLQ와 MFQ가 등장하게 됩니다.
첫 번째 MLQ부터 소개드리겠습니다.

멀티 레벨의 큐를 가진다는 것.
즉, Ready Queue를 여러 개 가진다는 특징을 가지고 있습니다.
이 Ready Queue에 배정하는건 작업(or 우선순위)별 별도의 Ready Queue를 가지기 때문에 최초에 배정된 queue를 웬만해서는 벗어나지 않는다는 특징을 가지고 있습니다.
또한 각각의 Queue는 자신만의 스케줄링 기법을 사용하고 있습니다.
그로 인해 Queue 사이에는 우선순위 기반의 스케줄링을 사용합니다.
그래서 장점은 빠른 응답시간을 기대할 수 있다고 이해할 수 있겠습니다.
왜냐하면 각 Queue에 배정된 우선순위가 높은 프로세스들은 아무래도 중요할 것입니다.
그로 인해 빠른 응답시간을 기대할 수 있습니다.
하지만 단점도 존재합니다.
여러 개의 Queue를 관리함으로써 생기는 부하가 커질 수 있고 우선순위가 상대적으로 낮은 Queue에 대해서 똑같이 Starvation (무한 대기) 현상이 일어날 것입니다.
그림으로 이해해보겠습니다.

우선순위에 맞추어서 종목별 프로세스를 보여줍니다.
이처럼 시스템의 성격을 고려하여 각 우선순위에 맞게끔 결정될 수 있습니다.
아까 말했듯이 이 MLQ는 최초에 배정된 Queue를 벗어나질 못한다는 특징을 가지고 있습니다.
우선순위가 낮은 Ready - Queue에 담긴 프로세스들 중에도 중요할 수 있는 프로세스가 있을 수 있기 때문에 이를 극복하고 보완하기 위해 프로세스의 Queue 간 이동이 허용된 MLQ가 등장합니다.

특징은 우선순위가 동적일 것이라는 것과 선점 스케줄링이라는 특징이 있습니다.
즉, 피드백 (응답, 후기)에 따라 우선 순위를 조정하여 Queue간 이동을 허용할 수 있습니다.
이 기법의 가장 좋은 점은 SPN, SRTN, HRRN을 쓰지 않고도 저 기법과 유사한 효과를 낼 수 있습니다.

그러나 여전히 단점은 존재했습니다. 설계 및 구현이 복잡하고 스케줄링 부하가 컸습니다.
또한 이로 인해 무한 대기현상이 존재할 수 있는데요.
이를 막기 위해 우선순위가 높은 큐에 대해 규정 시간 할당량을 배정하여 프로세스의 특성에 맞는 형태로 시스템을 운영할 수 있게 해줍니다.

그리고 I/O Bounded는 시스템을 잠깐 쓰고 마는 것이라고 전해 말씀 드렸습니다.
시스템 입장에서는 얘들을 잠깐만 할당해주고 종료시키는 것이 제일 효율적일 것입니다.
따라서 프로세스가 block될 때 상위의 준비 큐로 진입하게끔 도울 수 있구요.
그리고 대기시간이 지정된 시간을 초과한 프로세스들을 상위 큐로 이동시켜 (에이징 기법) 효율을 높일 수 있습니다.

또한 MFQ에서는 시간 할당량 외에도 큐의 수나 우선순위 기준 등 여러 파라미터로 MFQ의 성능을 높일 수 있겠습니다.
여기까지가 스케줄링 알고리즘 기법들이었습니다.
감사합니다.
'CS > 운영체제' 카테고리의 다른 글
| [운영체제 Step 11] - 상호배제 솔루션(1) (0) | 2021.12.13 |
|---|---|
| [운영체제 Step10] - 프로세스 동기화 & 상호배제 (0) | 2021.12.13 |
| [운영체제 Step8] - 프로세스 스케줄링 알고리즘 (0) | 2021.12.08 |
| [운영체제 Step 7] - 프로세스 스케줄링 (0) | 2021.12.08 |
| [운영체제 Step 6] - 스레드 관리 (0) | 2021.12.07 |



